求解器模式
SunSolve Power 有三种求解模式:
- 单次求解
- 扫描
- 优化
在单次求解模式下,结果使用多个输入标签页上的输入值进行计算。一次模拟包含一次运行。
在扫描模式下,用户选择某些输入进行”扫描”。这些选定的输入从初始值逐步变化到最终值,结果将作为同一模拟下的多次运行返回。几乎所有输入(甚至材料)都可以进行扫描。
在优化模式下,用户选择某些输入进行优化并设定优化目标,其中目标包括”输出指标”以及该指标应最大化还是最小化。然后 SunSolve 确定满足优化目标的选定输入值。这需要 SunSolve 在同一模拟下进行多次运行。
请注意,SunSolve 的优化器采用遗传算法,非常适合复杂的优化,例如具有多个输入的优化。对于只有单个输入的简单优化,使用扫描可能更高效。
优化例程和选项
Section titled “优化例程和选项”现在我们描述优化例程。带下划线的词是用户选项。
优化求解器使用遗传算法来找到最优输入值。该算法遵循基于进化的方法,在多代中找到”最适合”的基因组合(优化输入)。
用户设置每代运行次数 。每次运行都填充了各个输入标签页上定义的所有输入,但不包括被选为优化输入(基因)的那些。优化输入的值将由优化例程分配。
在第一代中,运行次数为 或 中的较大者,其中 是正在优化的输入数量。基因值的选择使其覆盖每个输入的用户定义下限和上限之间的全部范围。第一代还包括用户的最佳猜测。
然后并行求解第一代中的所有运行,并整理输出指标。具有最佳输出指标(即最适合的运行)的运行被添加到”基因池”中。随着世代的继续,基因池将始终由最适合的运行组成,其中基因池的大小不能超过基因池中的运行次数 。
然后创建第二代运行,其中基因值通过基因池中运行的”交配”来选择。这个交配过程涉及混合分数 和最大突变 Mmax。下面将更详细地描述交配过程。
在第二代(以及所有后续世代)完成时,再次修改基因池,使其包含来自所有世代的 个最适合的运行。
世代将继续,直到满足以下终止条件之一:
- 用户通过点击停止 ■ 来停止模拟
- 达到最大运行次数
- 达到最大总光线数
- 达到时间限制
- 超过运行失败阈值 ,或
- 算法收敛(定义如下)
此时,给出最大输出指标的运行被定义为”最适合”。加载其基因输入进行最终运行,求解后给出优化结果。
前四个终止条件不言自明。
当基因池中失败运行的数量超过 时,将出现第五个终止条件。当光线追踪或电气求解例程中出现故障时,就会发生失败运行。如果出现这种情况,欢迎您向 PV Lighthouse 发送导致问题的 SIM 文件,我们将确定问题所在。
第六个终止条件,收敛,是最理想的条件。这意味着求解器找到了最优输入(受指定约束条件的限制)。
收敛的定义因光线追踪器采用的蒙特卡洛方法而变得复杂。由于蒙特卡洛方法是随机的(包含随机性),我们希望最优输入的不确定性相对于单次运行的随机行为的不确定性较小。
具体来说,我们将收敛定义为
其中 CIGP 表示基因池中运行的 95% 置信区间,CIBR 表示最佳运行的 95% 置信区间, 是用户定义的常数,称为收敛容差。
我们使用下图来演示这个收敛条件的含义。
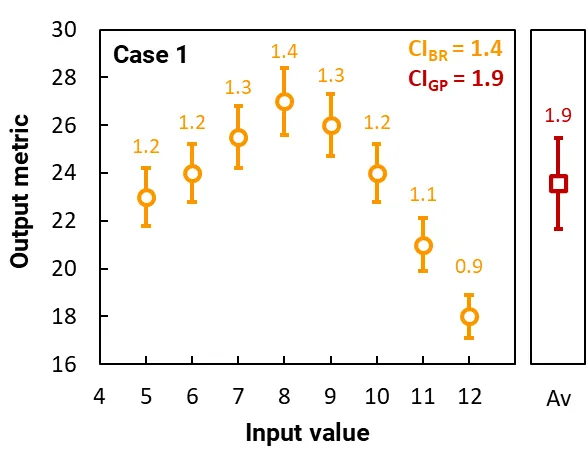
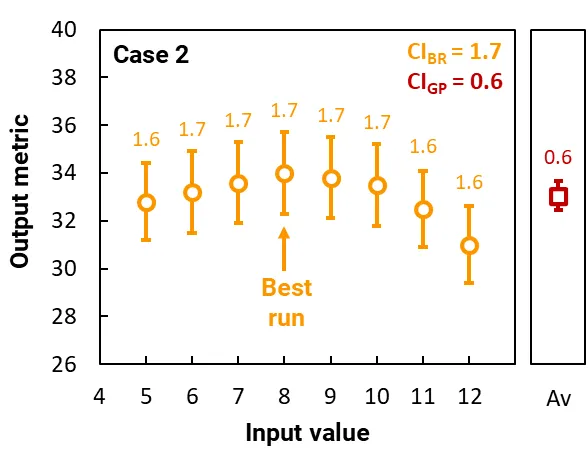
这些图表绘制了两个独立案例的结果。每个案例构成一个简单的模拟,包含一个输入变量和一个仅有 8 次运行的基因池,每次运行具有不同的输入值。
橙色圆圈绘制了基因池中每次运行的输出指标,橙色误差条(和标签)显示了它们的 95% CI。这个 CI 源于光线追踪的随机性质。最佳运行的 CI 是 CIBR。
红色方块绘制了输出指标的平均值,红色误差条(和标签)显示了基因池中运行的 95% CI;这个 CI 是 CIGP,它量化了基因池输出指标的变异性。(CIGP 的计算不依赖于运行的 95% CI。)
在案例 1 中,基因池包含具有高度可变输出指标的运行,其中 CIGP = 1.9,明显大于最佳运行的 CI,CIBR = 1.4。因此,如果 设置为 1,则模拟将不会收敛。另一代运行将填充更接近 8(最佳运行的值)的输入值,求解器将继续。
在案例 2 中,基因池包含具有相似输出指标的运行,其中 CIGP = 0.6,明显小于最佳运行的 CI,CIBR = 1.7。因此,如果 设置为 1,则模拟将已收敛。最优输入将是 8,最大输出指标将是 34 ± 1.7。
最佳的 次运行各自与从基因池中随机选择的另一个成员交配。这创建了 个子代,其基因是其父母基因的混合。这些基因的值,即它们的输入,由以下方法确定:
其中 R 是 0 到 1 之间的随机数,X 是感兴趣的输入值,ΔX = X1 - X2;其中 X1 和 X2 分别是两个父母中较适合和较差的输入值。
下图演示了二维优化的这种方法;即当有两个输入变量 X 和 Y 时。它将两个父母描绘为 X-Y 参数空间内的灰点,其中 X1、Y1 是较适合的,X2、Y2 是两个父母中较差的。新子代将在参数空间的阴影红色方块内的任何位置随机生成。

因此,较大的 Mmax 将导致下一代子代的更大变异性。较大的 Mmax 也将倾向于更稳健但更慢的优化算法。s 和 Mmax 的最优值在很大程度上取决于所解决的问题。
最后,我们提到算法会剪切”红色方块”,使其不会超出输入的用户定义下限和上限。